หลักการและการประยุกต์ใช้ทฤษฎีการทดสอบแบบคลาสสิก (CTT)
คู่มือนี้ให้การสำรวจเชิงลึกเกี่ยวกับหลักการและการใช้งานจริงของทฤษฎีการทดสอบแบบคลาสสิก (CTT) ซึ่งเป็นกรอบในการวัดทางจิตวิทยาและการศึกษาผ่านการเดินทางที่มีโครงสร้างมันนำไปสู่ต้นกำเนิดแนวคิดเช่นคะแนนจริงกรอบทางคณิตศาสตร์และสมมติฐานคู่มือนี้ช่วยให้คุณมีความรู้ที่จะเข้าใจและใช้หลักการ CTT ได้อย่างมีประสิทธิภาพนำเสนอการผสมผสานของบริบททางประวัติศาสตร์รายละเอียดทางเทคนิคและกลยุทธ์การปฏิบัติเพื่อเพิ่มความน่าเชื่อถือและความถูกต้องของการประเมินแคตตาล็อก

ต้นทาง
ทฤษฎีการทดสอบแบบคลาสสิก (CTT) เกิดขึ้นในช่วงปลายศตวรรษที่ 19 และครบกำหนดในช่วงทศวรรษที่ 1930 วางรากฐานสำหรับการวัดทางจิตวิทยาและการศึกษาสมัยใหม่การมีส่วนร่วมที่สำคัญเช่นงานของ Glickson ในปี 1950 เสริมสร้างรากฐานทางคณิตศาสตร์โดยเน้นความสำคัญของความน่าเชื่อถือและความถูกต้องในการประเมินช่วงเวลาหนึ่งเกิดขึ้นในปี 1968 กับสิ่งพิมพ์ที่สำคัญของลอร์ดและ Nowick ทฤษฎีทางสถิติของคะแนนการทดสอบทางจิตวิทยาซึ่งความเข้าใจขั้นสูงเกี่ยวกับคะแนนการทดสอบและปัจจัยที่มีอิทธิพลต่อพวกเขาเช่นลักษณะการทดสอบผู้ซื้อและบริบทด้านสิ่งแวดล้อมหลักการของ CTT ถูกนำไปใช้อย่างกว้างขวางในการทดสอบที่ได้มาตรฐานการจัดการกับความท้าทายเช่นอคติและการปรับแต่งรายการในขณะที่มุ่งมั่นในการวัดที่ถูกต้องและเป็นธรรมเมื่อเวลาผ่านไปทฤษฎีได้พัฒนาผ่านการมีอิทธิพลซึ่งกันและกันของการปฏิบัติและการวิจัยแบบไดนามิกการกำหนดวิธีการในปัจจุบันและที่เหลืออยู่สำหรับการประเมินทางการศึกษาและจิตวิทยา
ส่วนที่เหมาะสม
ในการวิจัยทางจิตวิทยาแนวคิดของคะแนนที่แท้จริงนั้นจำเป็นสำหรับการวัดพฤติกรรมและความรู้ความเข้าใจอย่างแม่นยำปราศจากอิทธิพลของข้อผิดพลาดในการวัดคะแนนจริงจะถูกกำหนดโดยการประเมินค่าเฉลี่ยหลายการประเมินเพื่อลดข้อผิดพลาดแบบสุ่มข้อผิดพลาดเหล่านี้อาจเกิดขึ้นได้จากปัจจัยต่าง ๆ เช่นเครื่องมือที่มีข้อบกพร่องบริบทสถานการณ์หรือสภาพจิตใจของผู้เข้าร่วมในระหว่างการทดสอบทำให้ใช้ในการปรับแต่งวิธีการประเมินตัวอย่างเช่นแบบสอบถามที่ออกแบบมาอย่างดีและเครื่องมือที่เชื่อถือได้สามารถลดข้อผิดพลาดเพิ่มความไว้วางใจในการค้นพบและปรับปรุงคุณภาพการวิจัยคะแนนที่แท้จริงยังมีผลกระทบในทางปฏิบัติเช่นการทำให้นักการศึกษาสามารถสร้างกลยุทธ์การประเมินที่ยุติธรรมโดยอาศัยการประเมินหลายครั้งมากกว่าคะแนนการทดสอบเดี่ยวคะแนนที่แท้จริงนั้นเชื่อมโยงกับความน่าเชื่อถือ (ความสอดคล้องของการวัด) และความถูกต้อง (ความแม่นยำของสิ่งที่วัดได้) โดยเน้นความสำคัญของเครื่องมือกลั่นเพื่อให้แน่ใจว่าการประเมินยังคงมีทั้งความสอดคล้องและมีความหมาย
กรอบทางคณิตศาสตร์
เฟรมเวิร์กทางคณิตศาสตร์ซึ่งแสดงโดยสมการ x = t + e อธิบายความสัมพันธ์ระหว่างคะแนนที่สังเกตได้ (x) คะแนนจริง (t) และข้อผิดพลาดในการวัด (E)ในบริบทนี้ข้อผิดพลาดแบบสุ่มมีส่วนช่วย E ในขณะที่ข้อผิดพลาดอย่างเป็นระบบจะถูกนำมาพิจารณาภายใน T คะแนนที่สังเกตได้สะท้อนให้เห็นถึงผลลัพธ์ของการวัดในขณะที่คะแนนจริงแสดงถึงค่าอุดมคติที่ปราศจากข้อผิดพลาดข้อผิดพลาดแบบสุ่มนั้นไม่สามารถคาดเดาได้และอาจเกิดขึ้นจากปัจจัยต่าง ๆ เช่นสภาพแวดล้อมหรือความแปรปรวนของผู้ทดสอบซึ่งมักจะลดลงผ่านการทดสอบซ้ำในทางกลับกันข้อผิดพลาดอย่างเป็นระบบมีความสอดคล้องและต้องการการตรวจสอบอย่างระมัดระวังของเครื่องมือการวัดและวิธีการเฟรมเวิร์กนี้เน้นความสำคัญของการลดข้อผิดพลาดเพื่อให้แน่ใจว่ามีความแม่นยำความน่าเชื่อถือและความถูกต้องในการประเมินกลยุทธ์การปฏิบัติเช่นสภาพแวดล้อมการทดสอบมาตรฐานและผู้ประเมินการฝึกอบรมเพิ่มความน่าเชื่อถือในการวัดการทำความเข้าใจความหมายของ x = t + e เป็นสิ่งสำคัญสำหรับการตีความข้อมูลอย่างรับผิดชอบหลีกเลี่ยงการพิจารณาผิดและการตัดสินใจขึ้นอยู่กับหลักฐานที่ดีกรอบนี้แสดงให้เห็นถึงการแสวงหาความแม่นยำในการวัดเพื่อปรับปรุงคุณภาพของข้อมูลเชิงลึกและผลลัพธ์
สมมุติฐาน
จากสมการที่จัดตั้งขึ้นเราสามารถได้รับสมมติฐานที่เกี่ยวข้องสามประการที่สำรวจความซับซ้อนของการวัดและข้อผิดพลาดในการประเมินทางจิตวิทยา
ครั้งแรกเมื่อมีการวัด N ข้อผิดพลาดโดยเฉลี่ยมีแนวโน้มที่จะเข้าใกล้ศูนย์การสังเกตนี้ทำให้เราสรุปได้ว่าคะแนนที่แท้จริงสอดคล้องกับคะแนนที่สังเกตได้โดยเฉลี่ยซึ่งแสดงทางคณิตศาสตร์เป็น t = e (x) หรือ e (e) = 0 สมมติฐานนี้เน้นความสำคัญของการมีขนาดตัวอย่างที่มีขนาดใหญ่เพียงพอเพื่อให้ได้ผลลัพธ์ที่เชื่อถือได้.ตัวอย่างที่มีขนาดใหญ่กว่ามีแนวโน้มที่จะลดผลกระทบของความผันผวนแบบสุ่มนำเสนอการแสดงคะแนนจริงที่ชัดเจนและแม่นยำยิ่งขึ้น
ประการที่สองเราเสนอว่าคะแนนที่แท้จริงและข้อผิดพลาดในการวัดดำเนินการอย่างอิสระระบุโดยρ (t, e) = 0. ความเป็นอิสระนี้จำเป็นสำหรับการรักษาความสมบูรณ์ของการประเมินทางจิตวิทยาเนื่องจากแสดงให้เห็นว่าอคติที่เป็นระบบไม่ได้ทำให้คะแนนที่แท้จริงในแง่การปฏิบัติการบรรลุความเป็นอิสระนี้จำเป็นต้องมีการทดสอบโปรโตคอลอย่างเข้มงวดและการใช้เครื่องมือที่ผ่านการตรวจสอบความถูกต้องซึ่งได้รับความน่าเชื่อถือและการประเมินความถูกต้องอย่างละเอียดมาตรการดังกล่าวสามารถช่วยบรรเทาอิทธิพลของตัวแปรที่อาจทำให้เกิดความสับสนซึ่งอาจบิดเบือนผลลัพธ์
ประการที่สามเราอ้างว่าข้อผิดพลาดที่เกิดขึ้นจากการทดสอบแบบขนานเป็นศูนย์แสดงเป็นρ (E1, E2) = 0 อย่างไรก็ตามการปฏิบัติจริงของการประเมินลักษณะทางจิตวิทยาซ้ำ ๆ ซ้ำ ๆ ผ่านการทดสอบแบบขนานมักเผชิญกับความท้าทายปัจจัยต่าง ๆ รวมถึงความจำเป็นสำหรับความสอดคล้องในลักษณะอาสาสมัครความยากลำบากในการทดสอบและความแตกต่างทำให้ความพยายามนี้ซับซ้อนขึ้นโดยทั่วไปการทดสอบครั้งเดียวจะดำเนินการกับกลุ่มซึ่งข้อผิดพลาดของแต่ละบุคคลจะถูกสันนิษฐานว่าจะสุ่มและกระจายตามปกติสมมติฐานนี้มีความสำคัญเนื่องจากอำนวยความสะดวกในการประยุกต์ใช้วิธีการทางสถิติสำหรับการวิเคราะห์ข้อมูลและการตีความที่มีประสิทธิภาพ
ความสัมพันธ์ระหว่างความแปรปรวนของคะแนนที่สังเกตคะแนนจริงและคะแนนข้อผิดพลาดภายในกลุ่มสามารถพูดชัดแจ้งผ่านสมการ SX = ST + SEสูตรนี้เป็นหลักสำหรับข้อผิดพลาดแบบสุ่มในขณะที่ความแปรปรวนของข้อผิดพลาดอย่างเป็นระบบถูกรวมเข้ากับความแปรปรวนของคะแนนจริงเมื่อเราเข้าใจลึกซึ้งยิ่งขึ้นเราสามารถปรับแต่งสมการนี้เป็น SX = SV + SI + SE โดยที่ SV หมายถึงความแปรปรวนที่เกี่ยวข้องกับวัตถุประสงค์การวัดและ SI หมายถึงความแปรปรวนที่เป็นอิสระจากมันมุมมองนี้ยอมรับว่าความแปรปรวนทั้งหมดไม่สามารถนำมาประกอบกับข้อผิดพลาดในการวัดการส่องสว่างความซับซ้อนของโครงสร้างทางจิตวิทยาและพฤติกรรมธรรมชาติหลายแง่มุม
โดยสรุปสมมติฐานเหล่านี้ส่องสว่างการมีปฏิสัมพันธ์ที่ซับซ้อนระหว่างคะแนนที่แท้จริงข้อผิดพลาดการวัดและความแปรปรวนของพวกเขาในการวัดทางจิตวิทยาการตระหนักถึงการเปลี่ยนแปลงเหล่านี้ไม่เพียง แต่เสริมสร้างความเข้มงวดของวิธีการประเมินของเรา แต่ยังช่วยเพิ่มความเข้าใจของเราเกี่ยวกับโครงสร้างทางจิตวิทยาที่เราตั้งเป้าหมายที่จะวัด
เกี่ยวกับเรา
ALLELCO LIMITED
อ่านเพิ่มเติม
สอบถามรายละเอียดเพิ่มเติมอย่างรวดเร็ว
กรุณาส่งคำถามเราจะตอบกลับทันที

พื้นฐาน IRQ: คำขอขัดจังหวะคืออะไรและทำงานอย่างไร?
บน 31/12/2024
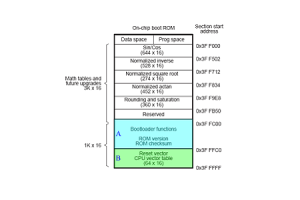
ตารางเวกเตอร์ขัดจังหวะ: สถาปัตยกรรมการจัดการและแอปพลิเคชัน
บน 31/12/2024
โพสต์ยอดนิยม
-

คอมพิวเตอร์ชุดคำสั่งที่ซับซ้อน: พวกเขาเปลี่ยนการคำนวณอย่างไร?
บน 17/04/8000 147721
-

USB-C Pinout และคุณสมบัติ
บน 17/04/2000 111778
-

การใช้ Xilinx Unified Simulation Primitives: คู่มือที่ครอบคลุมสำหรับการออกแบบและการจำลอง FPGA
บน 17/04/1600 111327
-
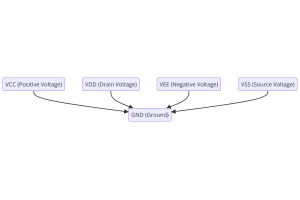
การทำความเข้าใจแรงดันไฟฟ้าของแหล่งจ่ายไฟในอิเล็กทรอนิกส์ VCC, VDD, VEE, VSS และ GND
บน 17/04/0400 83649
-

คู่มือเชื่อมต่อ RJ45: Pinout, การเดินสาย, ประเภทสายเคเบิลและการใช้งาน
บน 01/01/1970 79339
-

คู่มือที่ดีที่สุดสำหรับรหัสสีลวดในระบบไฟฟ้าที่ทันสมัย
วิธีที่ระบบไฟฟ้าของเราใช้สีไม่ได้มีไว้สำหรับรูปลักษณ์ตอนนี้สีลวดแต่ละอันบ่งบอกถึงฟังก์ชั่นเฉพาะทำให้ง่ายต่อการระบุและจัดการส่วนประกอบไฟฟ้าอย่างถูกต้องระหว่างการติดตั้งและบำรุงรักษาสิ่งนี้ไม่เพียง แ...บน 01/01/1970 66804
-
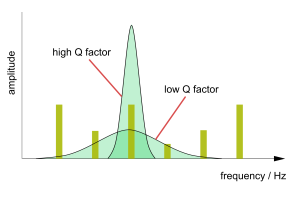
คุณภาพ (q) ปัจจัย: สมการและแอปพลิเคชัน
ปัจจัยด้านคุณภาพหรือ 'Q' เป็นสิ่งสำคัญเมื่อตรวจสอบว่าตัวเหนี่ยวนำและ resonators ทำงานได้ดีเพียงใดในระบบอิเล็กทรอนิกส์ที่ใช้ความถี่วิทยุ (RF)'Q' วัดว่าวงจรช่วยลดการสูญเสียพลังงานและส่งผลกระทบต่อช่วง...บน 01/01/1970 62965
-

คู่มือการล้างวาล์ว: ฟังก์ชั่นอาการการทดสอบและการเปลี่ยนประสิทธิภาพของเครื่องยนต์ที่ดีที่สุด
วาล์วล้างเป็นส่วนสำคัญของระบบรถยนต์ที่ช่วยให้อากาศสะอาดโดยการจัดการไอระเหยเชื้อเพลิงก่อนที่พวกเขาจะสามารถหลบหนีไปสู่ชั้นบรรยากาศได้สิ่งนี้ไม่เพียง แต่ช่วยสิ่งแวดล้อมด้วยการลดมลพิษ แต่ยังทำให้รถทำงา...บน 01/01/1970 62854
-
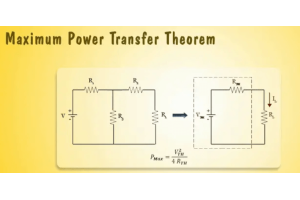
บรรลุประสิทธิภาพสูงสุดด้วยทฤษฎีการถ่ายโอนพลังงานสูงสุด
ทฤษฎีบทการถ่ายโอนพลังงานสูงสุดอธิบายว่าพลังงานจากแหล่งกำเนิดเช่นแบตเตอรี่หรือเครื่องกำเนิดไฟฟ้าจะไหลไปยังโหลดที่เชื่อมต่อได้อย่างไรมันแสดงเงื่อนไขที่แน่นอนที่โหลดได้รับพลังงานมากที่สุดบทความนี้ครอบ...บน 01/01/1970 54046
-

ข้อมูลจำเพาะและความเข้ากันได้ของแบตเตอรี่ A23
แบตเตอรี่ A23 เป็นแบตเตอรี่รูปทรงกระบอกขนาดเล็กที่มีแรงดันไฟฟ้าสูงเรียกอีกอย่างว่า 23A, 23AE หรือ MN21 มันทำงานที่ 12 โวลต์และสูงกว่าแบตเตอรี่ AA หรือ AAA มากการออกแบบพิเศษทำให้เหมาะสำหรับ...บน 01/01/1970 52032
หมายเลขชิ้นส่วนร้อน
-

GRM1886S1H151JZ01D
Murata Electronics
CAP CER 150PF 50V S2H 0603
NX2422CMTR
Microsemi Corporation
IC PWM CONTROLLER
MT9P031I12STC-DR
onsemi
SENSOR IMAGE COLOR CMOS 48-LCC
ACS711EEXLT-31AB-T
Allegro MicroSystems
SENSOR CURRENT HALL 31A AC/DC
MAXQ1050-BNS+
Analog Devices Inc./Maxim Integrated
MCU USB ASYMMETRIC CRYPTO TQFN
74279228111
Würth Elektronik
FERRITE BEAD 110 OHM 0603 1LN
LTC1174HVCS8#PBF
Analog Devices Inc.
IC REG BUCK BST ADJ 8SOIC
MC3632
Memsic Inc.
3-AXIS ACCELEROMETER
SST12LP18E-QX8E
Microchip Technology
IC AMP 802.11B/G/N 2.4GHZ 8XSON
MPC8260ACZUMHBB
NXP USA Inc.
IC MPU MPC82XX 266MHZ 480TBGA
F931E105MAA
KYOCERA AVX
CAP TANT 1UF 20% 25V 1206
CL31C221JGFNNNF
Samsung Electro-Mechanics
CAP CER 220PF 500V NP0 1206
VI-710483B
Vicor Corporation
DC DC CONVERTER
IS486E
SHARP/Socle Technology
LIGHT DETECTOR OPIC SCHMITT-TRIG
BZT52B68-E3-08
Vishay General Semiconductor - Diodes Division
DIODE ZENER 68V 410MW SOD123
TPS61187RTJR
Texas Instruments
IC LED DRVR RGLTR PWM 30MA 20QFN
QMJ325B7224KNHT
Taiyo Yuden
CAP CER 0.22UF 250V X7R 1210
1808GA330JAT9A
KYOCERA AVX
CAP CER 33PF 2KV C0G/NP0 1808 -

SCS302AHGC9
Rohm Semiconductor
DIODE SIC 650V 2.15A TO220ACP
AOD66923
Alpha & Omega Semiconductor Inc.
MOSFET N-CH 100V 16.5A/58A TO252
JS28F160C3BD70A
Micron Technology Inc.
IC FLASH 16MBIT PAR 48TSOP I
LAN9221-ABZJ
Microchip Technology
IC ETHERNET CTRLR 16BIT 56-QFN
AT17LV128-10PI
Microchip Technology
IC SRL CONFIG EEPROM 128K 8-DIP
VI-B62-CW
Vicor Corporation
DC DC CONVERTER 15V 100W
AM25S09/BEA
Advanced Micro Devices
AM25S09 - MUX, QUAD 2 LINE INPUT
LE79555-4BVC
Microchip Technology
IC TELECOM INTERFACE 44TQFP
BZX84C13
Fairchild Semiconductor
DIODE ZENER 13V 0.25W 5% UNIDIR
VI-JNB-EY
Vicor Corporation
DC DC CONVERTER 95V 50W
GRM1885C1H5R0CZ01J
Murata Electronics
CAP CER 5PF 50V C0G/NP0 0603
Z8018008PSC
Zilog
IC MPU Z180 8MHZ 64DIP
GMJ107BB7474KAHT
Taiyo Yuden
CAP CER 0.47UF 35V X7R 0603
CL21C471JBANFNC
Samsung Electro-Mechanics
CAP CER 470PF 50V C0G/NP0 0805
IR3553MTRPBF
Infineon Technologies
IC HALF BRIDGE DRIVER 40A 2PQFN
STM32L451RCT6
STMicroelectronics
IC MCU 32BIT 256KB FLASH 64LQFP
FT24C08A-ETG-T
Fremont Micro Devices Ltd
IC EEPROM 8KBIT I2C 1MHZ 8TSSOP
24AA65/SM
Microchip Technology
IC EEPROM 64KBIT I2C 8SOIJ -

24LC128-E/MF
Microchip Technology
IC EEPROM 128KBIT I2C 8DFN
DS2761AE
Analog Devices Inc./Maxim Integrated
IC BATT MONITOR LI-ION 16TSSOP
GRM1555C1E2R8CZ01D
Murata Electronics
CAP CER 2.8PF 25V C0G/NP0 0402
MAX14526EEWP+T
Analog Devices Inc./Maxim Integrated
IC UMIC CHARGER DETECTION WLP
MIC5239-5.0YSTR
Micrel Inc.
LOW QUIESCENT CURRENT 500 MA MIC
TCMT1101
Vishay Semiconductor Opto Division
OPTOISOLATOR 3.75KV TRANS 4SOP
1N3324RA
Solid State Inc.
DO5 50 WATT ZENER DIODES
AD1580BRT-REEL7
Analog Devices Inc.
IC VREF SHUNT 0.08% SOT23-3
GRM1885C1H161JA01D
Murata Electronics
CAP CER 160PF 50V C0G/NP0 0603
LTC4261IGN#PBF
Analog Devices Inc.
IC HOT SWAP CTRLR -48V 28SSOP
EP1S80F1508C7
Intel
IC FPGA 1203 I/O 1508FBGA
IRF7450TRPBF
Infineon Technologies
MOSFET N-CH 200V 2.5A 8SO
LP3966ESX-2.5
Texas Instruments
IC REG LIN 2.5V 3A DDPAK/TO263-5
UCC3819D
Texas Instruments
IC PFC CTR AVERAGE 250KHZ 16SOIC
TMS320C6748EZCEA3
Texas Instruments
IC DSP FIX/FLOAT POINT 361NFBGA
LP3985ITLX-2.5
Texas Instruments
IC REG LINEAR 2.5V 150MA 5DSBGA
SK320A
Taiwan Semiconductor Corporation
DIODE SCHOTTKY 200V 3A DO214AC
DS18S20+
Analog Devices Inc./Maxim Integrated
SENSOR DIGITAL -55C-125C TO92-3